

Every major AI vendor now supports the Model Context Protocol. The framing is almost always the same: MCP is the universal connector for AI agents in the enterprise. That framing sets up a false choice. MCP, REST/HTTP APIs, and Apache Kafka are not alternatives. They solve different problems at different layers of the architecture. Treating them as competing options produces systems that are fragile exactly where they need to be reliable.
These three technologies can and do coexist in the same architecture. The question is not which one to pick. It is which one belongs where, and what the tradeoffs are when more than one could technically do the job. This article maps that decision: what each technology is built for, where the boundaries are, and where the genuine gray areas lie.
1. What Is MCP and What Is It Built For?
Anthropic introduced the Model Context Protocol in November 2024 as an open standard for connecting AI assistants to external tools and data sources. Before MCP, every AI model required a custom connector to each external system. Three models, ten systems: thirty custom integrations to build and maintain. MCP collapses that to one standard interface. Any compliant client talks to any compliant server without prior coordination.
OpenAI adopted MCP in March 2025. Google DeepMind confirmed support in April 2025. By December 2025, MCP had reached over 97 million monthly SDK downloads across Python, TypeScript, Java, Kotlin, C#, and Swift. Anthropic donated the protocol to the Agentic AI Foundation under the Linux Foundation, with AWS, Google, Microsoft, Bloomberg, and OpenAI as platinum members. MCP is no longer a developer experiment.
Signals of enterprise maturity are arriving quickly: AI agents paying for API access autonomously, cross-SDK interoperability between Anthropic and OpenAI converging on MCP Resources, composable enterprise workflows where agents read tool signatures and compose cross-system flows without predefined paths, and an official MCP Registry launched in late 2025 as the community-driven server directory. The 2026 roadmap focuses on scalable transport, agent-to-agent communication, governance maturation, and enterprise readiness covering audit trails and SSO-integrated authentication.
MCP handles tool access: how an agent calls an external capability. It does not handle agent-to-agent coordination, which is the domain of protocols like Google’s Agent-to-Agent (A2A). MCP and A2A are complementary and address different layers of agentic architecture. The moment MCP is asked to do more than tool access, the architecture starts to break.
Security maturity is still catching up with adoption
Most incidents disclosed in 2025 and early 2026 are implementation failures, not protocol flaws. An Endor Labs analysis of 2,614 MCP implementations found 82% use file system operations prone to path traversal and 67% use APIs related to code injection. Enterprise-grade authentication with OAuth 2.1 and SAML/OIDC is on the 2026 roadmap but still in progress.
The practical controls for today: apply least privilege, limit MCP server access to only the systems and data each tool requires, and monitor tool definitions for unexpected changes.
2. MCP vs. REST/HTTP API
MCP and REST/HTTP APIs serve different consumers and should not be treated as interchangeable.
REST is an architectural style built on HTTP, widely adopted but with no fixed conventions for discovery, error formats, or method naming. Well-designed REST APIs backed by OpenAPI specifications work well for direct, programmatic data access when a native SDK or versioned API already exists and teams know how to operate it.
MCP enforces consistency at the interface level because the consumer is an AI model that cannot tolerate creative API interpretation. MCP standardizes how a tool is called. It does not standardize what the tool returns, how fresh that data is, or whether two agents calling the same tool simultaneously see the same state. For direct data access to vector stores, databases, or business application APIs, a well-governed REST API, native SDK, or Kafka Connect integration is almost always the better choice: lower latency, no protocol overhead, mature tooling. For giving AI agents standardized, discoverable access to a broader set of tools across vendors and frameworks, MCP is the right layer. The two are complementary, not competing.
Tool design matters as much as the protocol choice
One important nuance on tool design: mapping one-to-one from existing APIs to MCP tools rarely works well. What matters is tool granularity, smart metadata, and thoughtful assembly of the MCP layer. An MCP server that exposes well-structured, semantically rich tools is what allows an AI agent to reason about capabilities and compose workflows. This is reminiscent of the composability questions from the enterprise SOA (Service-oriented Architecture) era. SOA promised flexible service composition but delivered integration chaos when governance, metadata quality, and service granularity were treated as afterthoughts. MCP faces the same risk. The protocol is sound; what determines success is the discipline applied to how tools are defined, documented, and assembled.
What MCP does not do
What MCP does not do matters as much as what it does. It does not manage data, guarantee message delivery, enforce governance, or guarantee consistency across systems. It is an interface layer, not a data pipeline.
That boundary becomes even clearer when looking at what Kafka does, which is structurally different from both MCP and REST.
3. Apache Kafka: Event Broker, Decoupling, and the Backbone Role
Operational data is the live data that runs business processes: order states, inventory levels, transaction records, customer accounts, risk scores. It originates in systems like SAP, Salesforce, Oracle, and mainframes, and it changes continuously.
Kafka is architecturally different from both HTTP and MCP in one way that matters most: it decouples producers and consumers through a persistent, ordered, append-only log.
With HTTP or MCP, the caller and the callee are coupled at request time. Every integration is point-to-point. If the target system is slow or unavailable, the caller is directly affected.
Kafka breaks that coupling entirely. A producer writes an event once. Any number of consumers read it independently, at their own pace, using their own communication paradigm. One consumer processes records in real time. Another runs nightly batch analytics over the same events. A third powers a stream processing pipeline. A fourth writes results to a data lake via Apache Iceberg. All of them consume the same underlying data product. None of them affects the others.
Kafka supports three consumption patterns from a single event stream: streaming, request-response, and batch. The event exists once; each consumer is independent. This is the pub/sub event broker model, and it is what makes Kafka the integration backbone between operational and analytical systems.
The diagram below shows this decoupling: a single Kafka topic serving real-time applications, HTTP-based consumers, batch analytics, and MCP agent interfaces simultaneously.
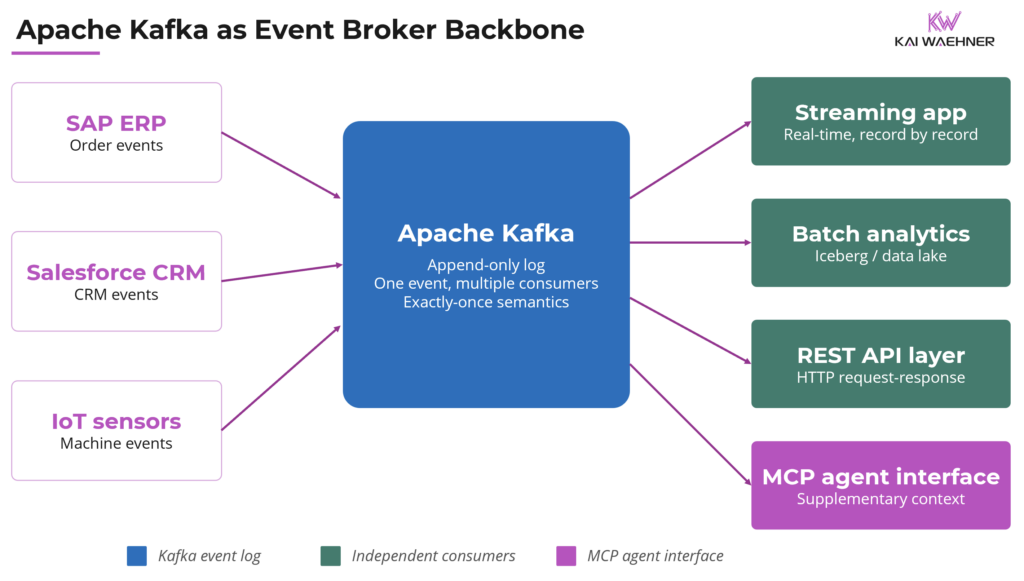
Stream processing with Kafka Streams and Apache Flink
Stream processing is a core complement to Apache Kafka, extending the platform from event transport into real-time data processing and decisioning.
Kafka Streams is a lightweight Java library embedded in applications. It is well suited for streaming ETL and simple to medium stateful stream processing without requiring a separate cluster. It integrates closely with existing JVM-based services.
Apache Flink is a distributed stream processing engine designed for more complex workloads. It supports Java, Python, and SQL APIs, making it accessible to both application developers and data engineers. Flink runs as a dedicated cluster or in managed environments and is built for high-scale scenarios such as multi-stream joins, event-time processing, large state management, exactly-once semantics, Complex Event Processing (CEP), real-time analytics, and AI model inference.
Both approaches extend Kafka with processing capabilities. The choice depends on workload complexity, required deployment model, and preferred programming language, not on replacing Kafka’s role as the event streaming backbone. A detailed comparison is available in the post Apache Kafka and Apache Flink: A Match Made in Heaven.
Operational and analytical integration, including the data lakehouse
Kafka is not only for operational data integration. It serves as the ingestion layer into data lakes, feeds real-time analytical pipelines, enables stream processing with embedded AI models, and connects business applications bidirectionally. A governed data streaming platform provides schema registry, lineage tracking, role-based access control, and exactly-once delivery semantics across all of that. It serves both operational and analytical use cases and acts as the bridge between those two worlds. For how streaming and the lakehouse converge via Apache Iceberg, see Data Streaming Meets Lakehouse.
Kafka’s append-only commit log is the foundation of data consistency across the enterprise. Every downstream consumer sees the same data in the same order. That is not just a performance feature. It is what prevents the architecture where every system has its own version of the truth.
4. The Tradeoffs: It Is Not Black and White
The choice between MCP, REST/HTTP APIs, and Kafka is rarely clean. All three can play a role in the same architecture.
REST/HTTP APIs work well for operational data access when volume is moderate and a well-governed API already exists. A REST API backed by a Kafka-derived serving layer can return consistent, current data. The API is the interface; the streaming platform is what makes the data trustworthy behind it. A financial services firm exposing account balances via REST is not doing it wrong, as long as those balances are derived from a governed, consistent data source rather than pulled directly from a source system on every request.
Kafka becomes the clear choice when data is high-volume or high-velocity, when multiple consumers need the same events, when ordering and exactly-once delivery matter, or when the same events need to feed operational applications, analytical pipelines, and AI agents simultaneously.
MCP fits best when access is supplementary, loosely coupled, and low-frequency. A support agent looking up a ServiceNow ticket before drafting a response, or a sales assistant pulling the latest slide deck from Google Drive before a call, are good fits. The key test is simple: does it matter if the data the agent receives is a few seconds or minutes old? If yes, MCP should not own that responsibility. If no, MCP is the right interface.
SAP: clean separation between ERP integration and developer tooling
The boundary between MCP and REST is not a choice between two equivalent options for the same integration. SAP is the clearest example of a clean separation. SAP exposes extensive REST and OData APIs for ERP integration: order management, finance, supply chain, procurement, and HR data flowing bidirectionally between SAP and other enterprise systems. SAP’s MCP servers serve an entirely different purpose: developer tooling for ABAP code generation, CAP application development, UI5 and Fiori assistance, and operational tasks like transport validation and incident management. An architect connecting SAP order events to downstream systems uses OData and Kafka Connect. A developer asking an AI coding assistant to generate ABAP code uses the SAP MCP server. Different consumers, different use cases, different data. No overlap.
Salesforce and ServiceNow: same data, different consumer
Salesforce and ServiceNow follow a different pattern. Their MCP servers wrap the same underlying REST APIs and expose the same underlying data, but for a different consumer. A developer-written integration calls the Salesforce REST API directly with known endpoints and hardcoded logic. An AI agent calls the Salesforce MCP server, which wraps that same API to make it discoverable and stateful for an agent that cannot read documentation or manage its own session state. The data is identical. The access path differs based on who is consuming it. This is not a free choice between equivalent options. It is the same system serving two different client types through two different interface layers.
REST vs. Kafka for operational data: the harder call
The harder boundary is between REST and Kafka for operational data. Both can technically serve it, and that is where the real architectural decision lies.
REST is simpler to start with but introduces point-to-point coupling, integration spaghetti at scale, and consistency risks when the same data needs to reach multiple consumers. Kafka is more complex to operate but provides the decoupling, consistency, and governance that enterprise architectures require when the same data needs to reach many consumers reliably.
The two are not mutually exclusive. A common and well-proven pattern combines both: Kafka handles the event backbone, decoupling, and consistency, while a REST layer sits on top for synchronous request-response access, API management integration, or compatibility with systems that cannot speak the native Kafka protocol. This is particularly common in mobile applications, legacy system integration, and API gateway architectures. For a detailed look at how REST and Kafka complement each other in practice, see Request-Response with REST/HTTP vs. Data Streaming with Apache Kafka.
5. Decision Framework: MCP, REST/HTTP, or Kafka?
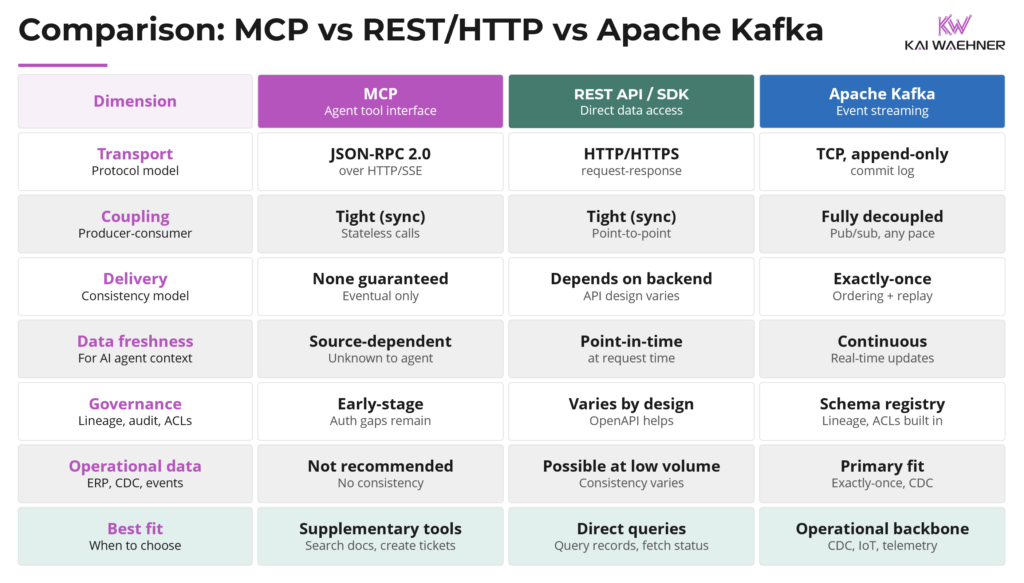
Choosing between MCP, REST/HTTP, and Kafka is not a single decision but a set of tradeoffs that depend on data volume, consumer type, consistency requirements, and what is already in production. The comparison table below makes those tradeoffs concrete across eight dimensions.
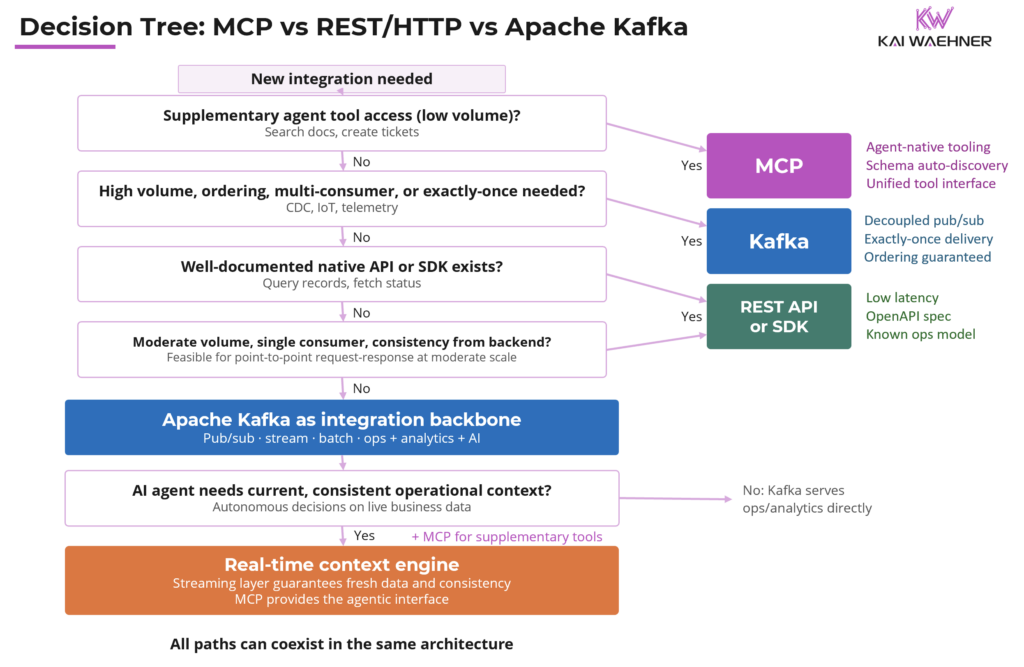
When to use which: a guide to the decision tree
The decision tree below walks through the same logic as a series of questions, routing to the right choice based on the integration’s actual requirements.
Use MCP when the integration is supplementary and tool-like: Slack, Google Drive, ServiceNow tickets, internal knowledge bases. The agent needs context to act, not a stream of events to react to. Eventual consistency is acceptable. Apply least privilege, monitor tool definitions for changes, and isolate MCP servers from production systems.
Use a REST/HTTP API or native SDK when a well-documented API or SDK already exists and the engineering team knows how to operate it. The access pattern is direct, moderate-volume, and latency-sensitive. REST is also a reasonable choice for operational data when the backend is a governed Kafka-derived serving layer and consistency properties are inherited, not assumed.
Use Apache Kafka when data is high-volume or high-velocity, when multiple consumers need the same events, when ordering and exactly-once delivery matter, or when governance, lineage, and auditability are non-negotiable. Kafka is also the right choice when the same data needs to feed operational applications, real-time analytics, data lakes, and AI agents simultaneously.
Use the real-time context engine when an AI agent needs current, consistent operational context for autonomous decisions. Kafka and Flink govern the data. MCP provides the agent interface. The consistency guarantee comes from the streaming layer, not from MCP.
The practical question is not which protocol to choose. It is whether the data architecture underneath the agents can be trusted. Agents making autonomous decisions about inventory, risk, or customer service are only as reliable as the data they act on.
6. Where MCP and Kafka Work Together: The Real-Time Context Engine
There is one pattern where MCP and data streaming complement each other directly: the real-time context engine.
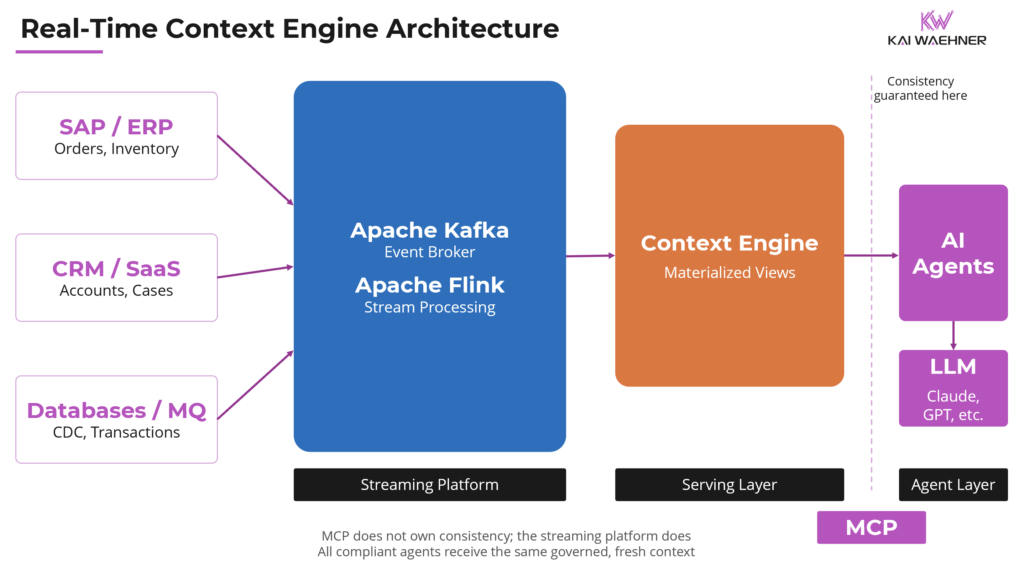
Kafka and Flink process and govern the data: ingesting from operational systems, applying transformations and filters, producing real-time materialized views. Those views are then exposed to AI agents through a standardized MCP interface. The streaming platform owns the data, its freshness, and its consistency guarantees. MCP owns the interface to the agent. Neither layer bleeds into the other’s responsibility.
Data consistency is not delegated to MCP. It is enforced upstream inside the streaming platform before the MCP interface comes into play. The agent calls a tool and receives context that is current, governed, and consistent, not because MCP guarantees it, but because the streaming platform does. Any compliant AI agent, whether Claude, ChatGPT, Amazon Bedrock, LlamaIndex, or CrewAI, can call the context engine and receive current context from operational systems without needing to understand Kafka topics, Flink jobs, or schema evolution.
An agent routing shipments from yesterday’s inventory, approving transactions against a risk score from three hours ago, or reading an account balance that has not propagated: none of these is reliable. A real-time context engine eliminates this class of error at the source, reduces hallucinations, lowers inference cost, and anchors decisions to current operational reality.
From data freshness to agent governance
Enterprise readiness for this pattern also depends on how agents are governed once deployed. Trust, control, and accountability become central once agents start chaining decisions across domains. The context engine is the data layer of that answer. Governance of the agents themselves, covering what they are permitted to do, under what conditions, and with what audit trail, is the other half. This is the dimension enterprise buyers are actively evaluating when selecting agent orchestration platforms.
The diagram below shows how the three layers fit together: the streaming platform as the data backbone, the context engine as the governed serving layer, and MCP as the clean interface to agents.
7. Conclusion: One Protocol, One Job
MCP has earned its place in the enterprise architecture stack. What it has not yet earned is the role of universal integration layer, and understanding that distinction is what this article has been about.
The broader architecture this sits inside connects three interdependent pillars. Event-driven data integration, with Kafka as the backbone, moves data reliably between operational and analytical systems and delivers governed data products to every consumer. Process intelligence is the orchestration layer that determines which decisions to automate, in what sequence, and under what conditions, giving agentic workflows the structure and governance they need to be trustworthy. Trusted agentic AI is where MCP plays its role: the standardized, governed interface through which agents access external tools and context, anchored to real data by the streaming layer beneath it.
For a vendor-by-vendor analysis of trust and lock-in across the major AI platforms, see the Enterprise Agentic AI Landscape 2026.
For a deeper look at how the three pillars fit together as an enterprise architecture framework, see The Trinity of Modern Data Architecture: Process Intelligence, Event-Driven Integration, and Trusted Agentic AI.
One protocol, one job. That is the right way to use MCP.
Stay informed about the latest thinking on data integration, process intelligence, and trusted agentic AI by subscribing to my newsletter and following me on LinkedIn or X. And download my free book, The Ultimate Data Streaming Guide, a practical resource covering data streaming use cases, architectures, and real-world industry case studies.